

NVIDIAのBlackwell AIチップはMLPerfで記録的な性能を確保、Hopper H100&H200チップはMI300Xを上回り、さらに強力になり続ける。
MLPerf推論・AIベンチマークにおけるNVIDIAの優位性がBlackwell AIチップでさらに強固に、HopperはCUDAスタックの継続的な最適化によりさらに強力な性能向上を示す
NVIDIAのBlackwell AIチップは、ついにMLPerf v4.1で記録的なデビューを果たし、すべてのベンチマークで記録的な性能を確保しました。
今年後半にデータセンターに登場するNVIDIA Blackwell AIチップは、世代を超えた性能を最大4倍まで向上させ、市場最強のAIソリューションとして態勢を整えている。

本日NVIDIAは、MLPerf Inference v4.1において、以下を含むすべてのAIベンチマークで最高性能を達成したことを発表しました:
- Llama 2 70B (高密度LLM)
- Mixtral 8x7B MoE(スパース混合エキスパートLLM)
- 安定した拡散(テキストから画像へ)
- DLRMv2(レコメンデーション)
- BERT(自然言語処理)
- RetinaNet(物体検出)
- GPT-J 6B (高密度LLM)
- 3D U-Net(医用画像セグメンテーション)
- ResNet-50 v1.5(画像分類)
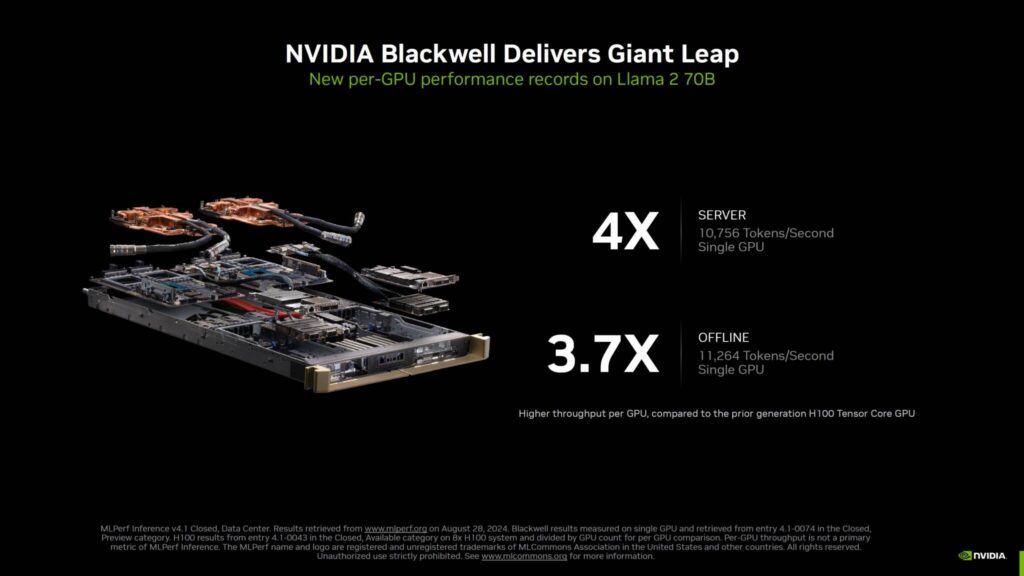
Llama 2 70Bにおいて、NVIDIAのBlackwell AIソリューションは、Hopper H100チップよりも大幅な向上を実現しています。
サーバーワークロードでは、単一のBlackwell GPUが4倍の性能向上(10,756トークン/秒)を提供し、オフラインシナリオでは、単一のBlackwell GPUが11,264トークン/秒と3.7倍の性能向上を提供します。
NVIDIAはまた、Blackwell GPU上で実行されるFP4を使用して、初めて公に測定された性能を提供しました。

Blackwellが約束された野獣である一方、NVIDIAのHopperは、CUDAスタックを通じてより多くの最適化が施され、さらに強力になり続けている。
H200とH100チップは、競合と比較して、また、560億パラメータ「Mixtral 8x7B」LLMのような最新のベンチマークにおいても、あらゆるテストにおいてトップクラスの性能を発揮します。

8個のHopper H200 GPUとNVSwitchを搭載したNVIDIA HGX H200は、Llama 2 70Bで強力なパフォーマンス向上を実現し、トークン生成速度は、1000W構成で34,864(オフライン)、32,790(サーバー)、700W構成で31,303(オフライン)、30,128(サーバー)トークン/秒です。
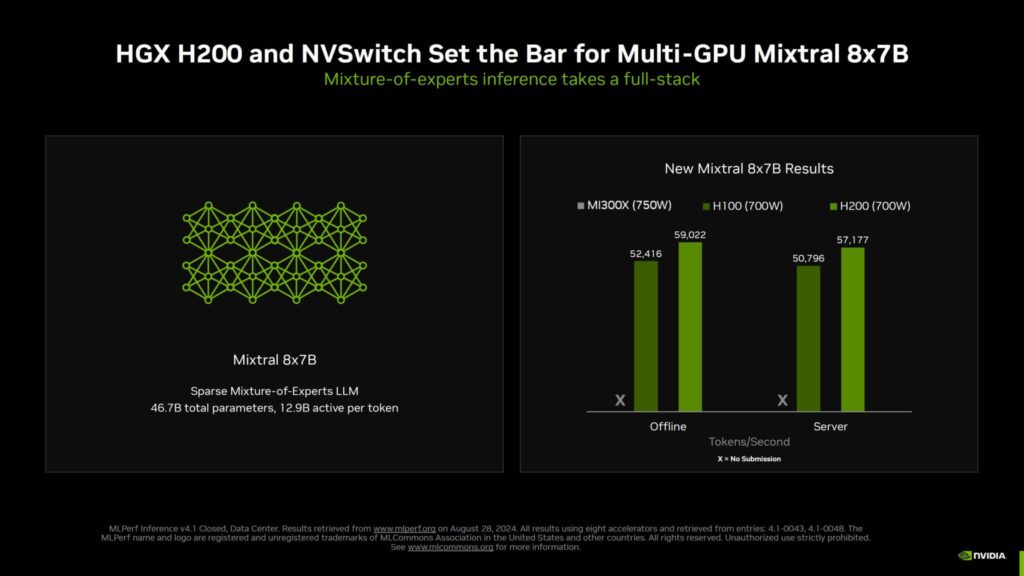
これはHopper H100ソリューションと比較して50%の向上である。
H100は、Llama 2において、AMD Instinct MI300Xソリューションよりも優れたAIパフォーマンスを提供します。
追加された性能は、Hopperチップの両方に適用されるソフトウェアの最適化と、H200チップに関連する80%高いメモリ容量と40%高い帯域幅のおかげです。
マルチGPUテストサーバーを使用したMixtral 8x7Bでは、NVIDIA H100とH200は、それぞれ最大59,022と52,416トークン/秒の出力を実現した。
AMDのInstinct MI300Xは、レッドチームが提出しなかったため、この特定のワークロードでは動作していないようだ。
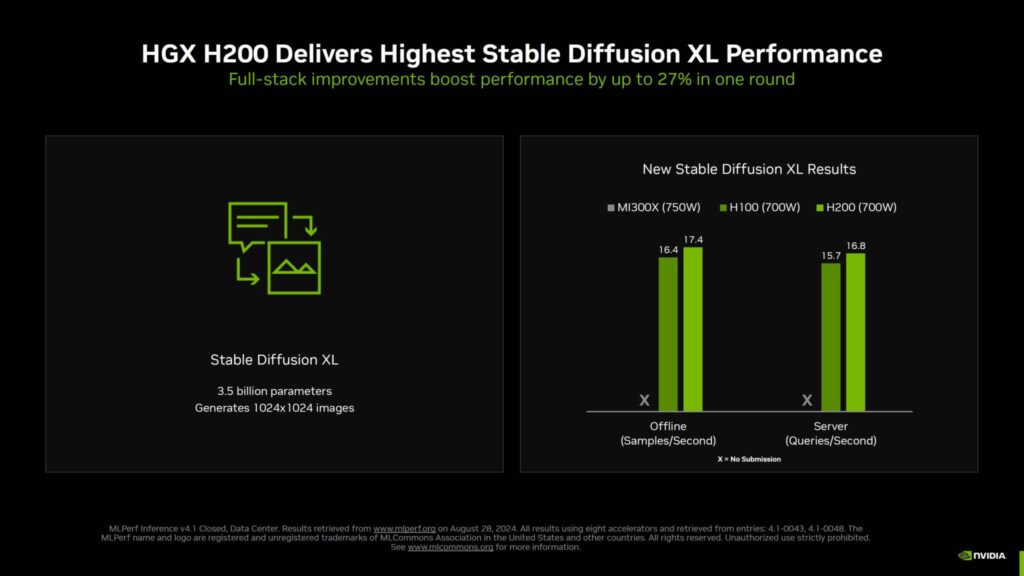
Stable Diffusion XLでも同様で、新しいフルスタックの改良により、Hopper AIチップのパフォーマンスが最大27%向上しているが、AMDはこの特定のワークロードでMLPerfをまだ提出していない。
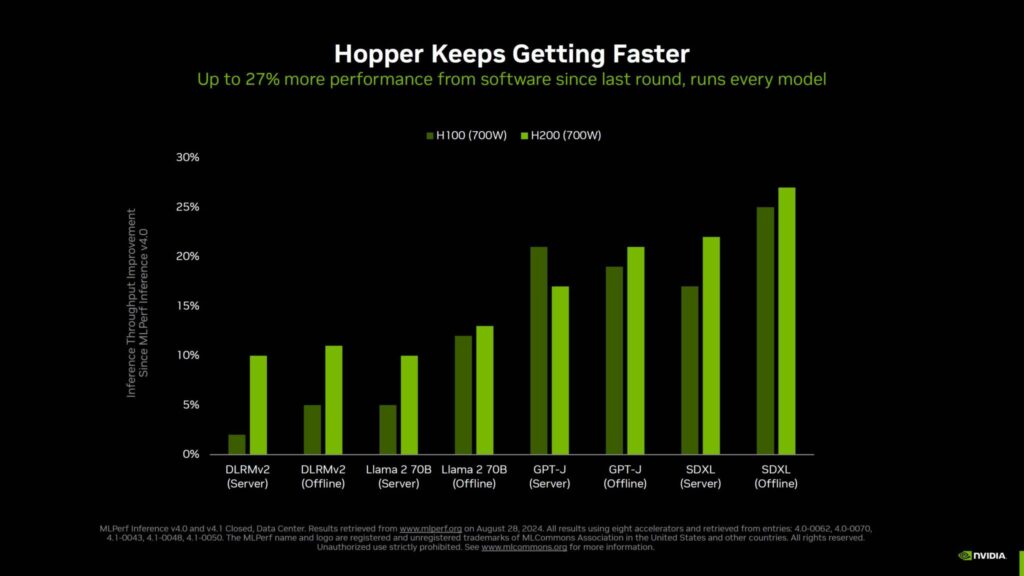
ソフトウェアを微調整するNVIDIAの努力は、大きな成果を上げている。
同社はMLPerfをリリースするたびに大幅な向上を遂げており、その利点はサーバー内でHopper GPUを稼働させている顧客に直接提供されています。
AIとデータセンターはハードウェアがすべてではありません。
ハードウェアは1つの要素ですが、それと同じくらい重要なもう1つの要素はソフトウェアです。
AIインフラに何百万ドルも投資する企業は、エコシステム全体を見ています。
NVIDIAはそのエコシステムを十分に備えており、世界中の企業やAI強豪企業に展開する準備が整っている。
だからこそ同社は今、さまざまなパートナーを通じてHGX H200の一般提供を発表しているのだ。

最適化が進んでいるのは、BlackwellやHopperといったヘビー級だけではありません。
Jetson AG Orinのようなエッジソリューションでさえ、MLPerf v4.0提出以降、6倍のブーストが見られ、エッジにおける生成AIのワークロードに大きな影響を与えている。




Blackwellが発売前にこれほど強力なパフォーマンスを示したことで、Hopperがそうであったように、AIに合わせた新アーキテクチャがさらに強力になり、来年後半にはBlackwell Ultraに最適化の恩恵が引き継がれることが期待される。
解説:
BlackwellがAIサーバー分野で強力な性能を発揮
Llama 2 70Bにおいて、Hopper H100と比較すると4倍の性能を発揮するようです。
さらにHGX200(700W)はLlama 2 70BにおいてMI300X(750W)の1.33倍の性能を発揮するとのこと。
BlackwellとMI300Xとの性能差はまだ出てきませんが、これから出荷が始まればさらに情報公開されていくと思われます。
本来BlackwellはMI325やMI350と対決することになるのでしょう。
現段階ではH100/H200にも若干下回る程度の性能でしかありません。
ROCmも少しずつ進歩していますが、今のところ同世代のNVIDIA製品には及んでいないかなあというのか感想です。
最も私はRDNA3とGeforceでしか比較したことはありません。
ネットでの結果を見ると同世代のCDNA製品やRadeon Proと結果はあまり変わってないかなという印象です。
AI用途においてROCmを使ったRDNA3は一世代前のAmpereよりやや劣るかなあといった感じです。
AMDがNVIDIA製品に追い付くにはしばらく時間がかかると同時にNVIDIA製品もハード・ソフトウェアの両方で進化し続けていますので追い付くのは難しいかなとも思います。
なんにせよ、これから発売されるBlackwellとMI325/MI350が対抗できるのかどうかは注目です。
Intelはまだ存在感を発揮できていませんので、ここに割って入れるようになったらすごいのかなと思います。
nVidia RTX4000SUPER



nVidia RTX4000


nVidia RTX3000シリーズGPU
RTX3060 12GB GDDR6

RTX3050 6GB

Copyright © 2024 自作ユーザーが解説するゲーミングPCガイド All Rights Reserved.