

AMDは、自社のInstinct GPUの競争力が、NVIDIAを自社のAIロードマップに全力で取り組ませたが、レッドチームは今後も手加減するつもりはないと述べている。
AMDは、年間AI Instinctアクセラレータのケイデンス、NVIDIAのBlackwell B100とHopper H200に対するMI325Xの競争力、そしてどのように緑の巨人を怖がらせてそのロードマップを加速させたかについて話している。
この詳細は、CRNが行ったAMDのデータセンター・ソリューション事業グループ担当エグゼクティブ・バイスプレジデント兼ジェネラル・マネージャー、フォレスト・ノーロッド氏へのインタビューから得られたもので、同氏は、NVIDIAにデータセンターAIロードマップのアクセルを強く踏ませたのは、AMDとそのInstinct GPUロードマップであり、現在では1年ごとのペースに移行していると述べている。
NVIDIAだけでなく、AMDとIntelもまた、2023年に始まった勢いを止めることなく、AIバンドワゴンに猛進している。
フォレストは、AI分野は急速なペースで進化を続けており、LisaのAI分野へのコミットメントにより、シリコンとソフトウェアの両面で継続的なイノベーションを通じ、顧客の需要に確実に応えていくと述べている。
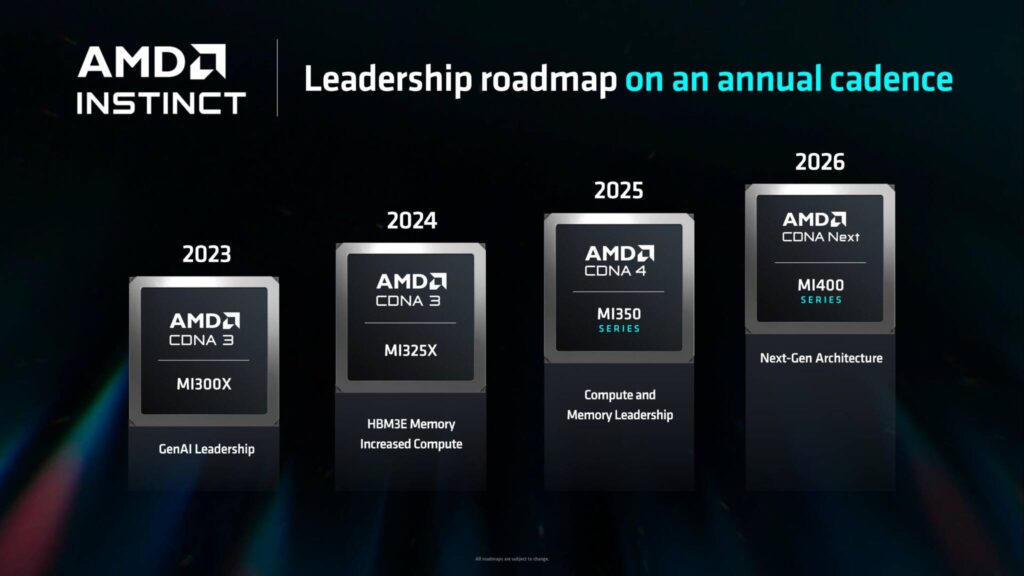
同社は、データセンターおよびコンシューマー向けの堅牢なROCmソフトウェア・スイートを微調整しており、最近、MI325、MI350、MI400シリーズという形で2024年から2026年まで利用可能なInstinct AIアクセラレータの膨大なポートフォリオを発表した。

フォレストの最も興味深いコメントは、今年Blackwell、来年Blackwell Ultra、そして2026年と2027年にそれぞれ次世代Rubinアクセラレータとそれに続くUltraと、ロードマップを加速させる最近のNVIDIAの後押しに関するものだった。
フォレスト氏によれば、NVIDIAは、AMDのInstinct MI300の発表という “Holy Crap “な瞬間の後、アクセルペダルを踏み込んだという。
フォレスト氏によれば、NVIDIAは「意図的に」アクセルを踏み込み、AMDや他のすべての人をAI分野から締め出そうとしたが、戦いは続いており、AMDはすぐには一歩も引かないとのことだ。
そしてもう1つのダイナミズムは、もちろん競争力だ。率直に言って、Nvidiaはアクセルを踏み込みました。AMDは本物の部品を手に入れ、本当の競争相手になりそうだ」と見て、非常に意図的にアクセルを踏み込み、私たちや他のすべての人たちを締め出そうとしたのです。だから、我々もそれに対応しているんだ。
フォレスト・ノーロッド – AMD幹部 (CRNより)
AMDは、データセンター側の研究開発に多くの投資を行っており、チップの生産も着実に増強しているという。
AMDはまた、NVIDIAの発表に今だけ反応していると思われたくない。

今後のMI325とMI350の刷新について語る際、AMDはこれらのAIアクセラレータがNVIDIAの発表との差をさらに縮めると述べている。
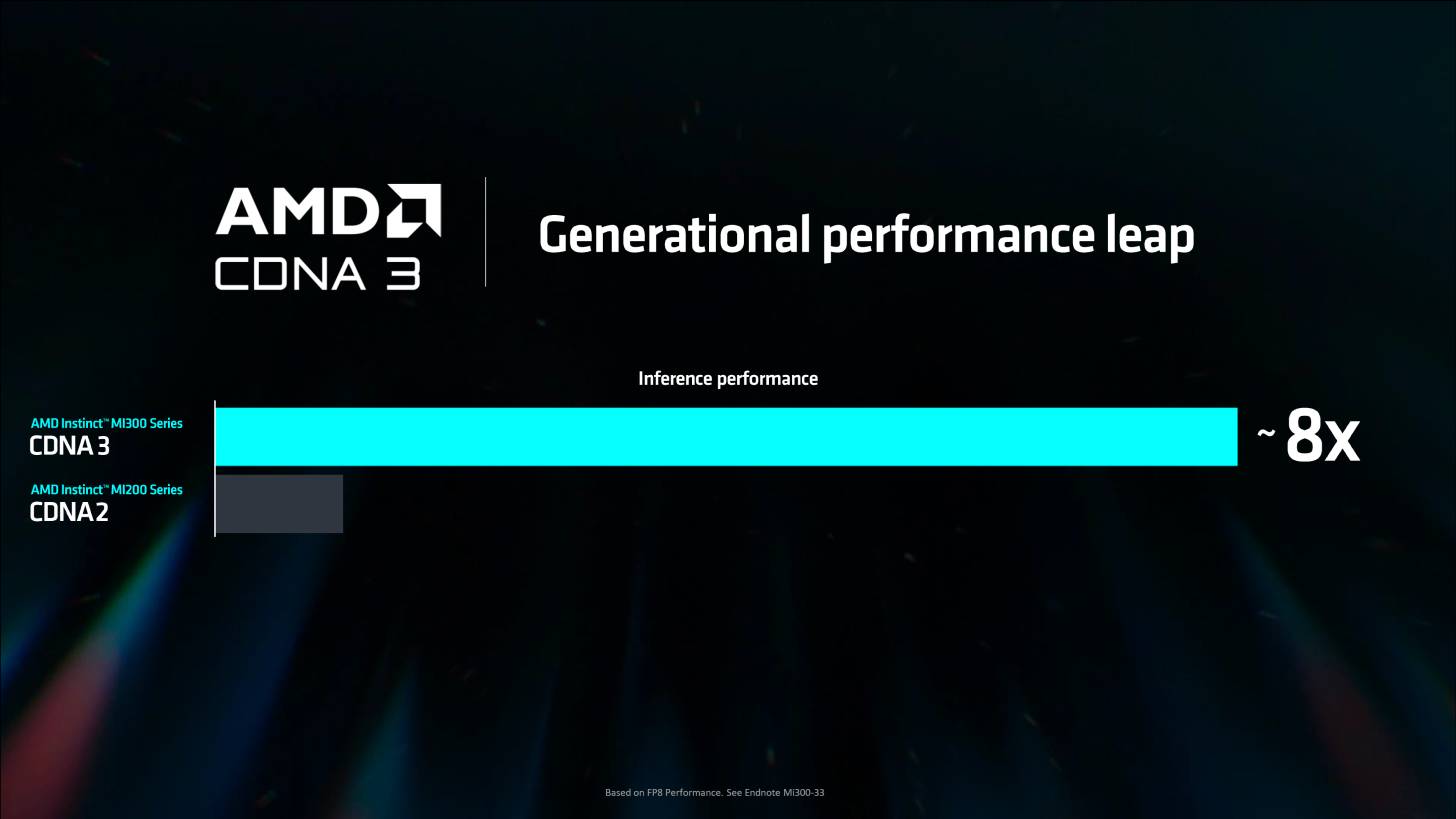
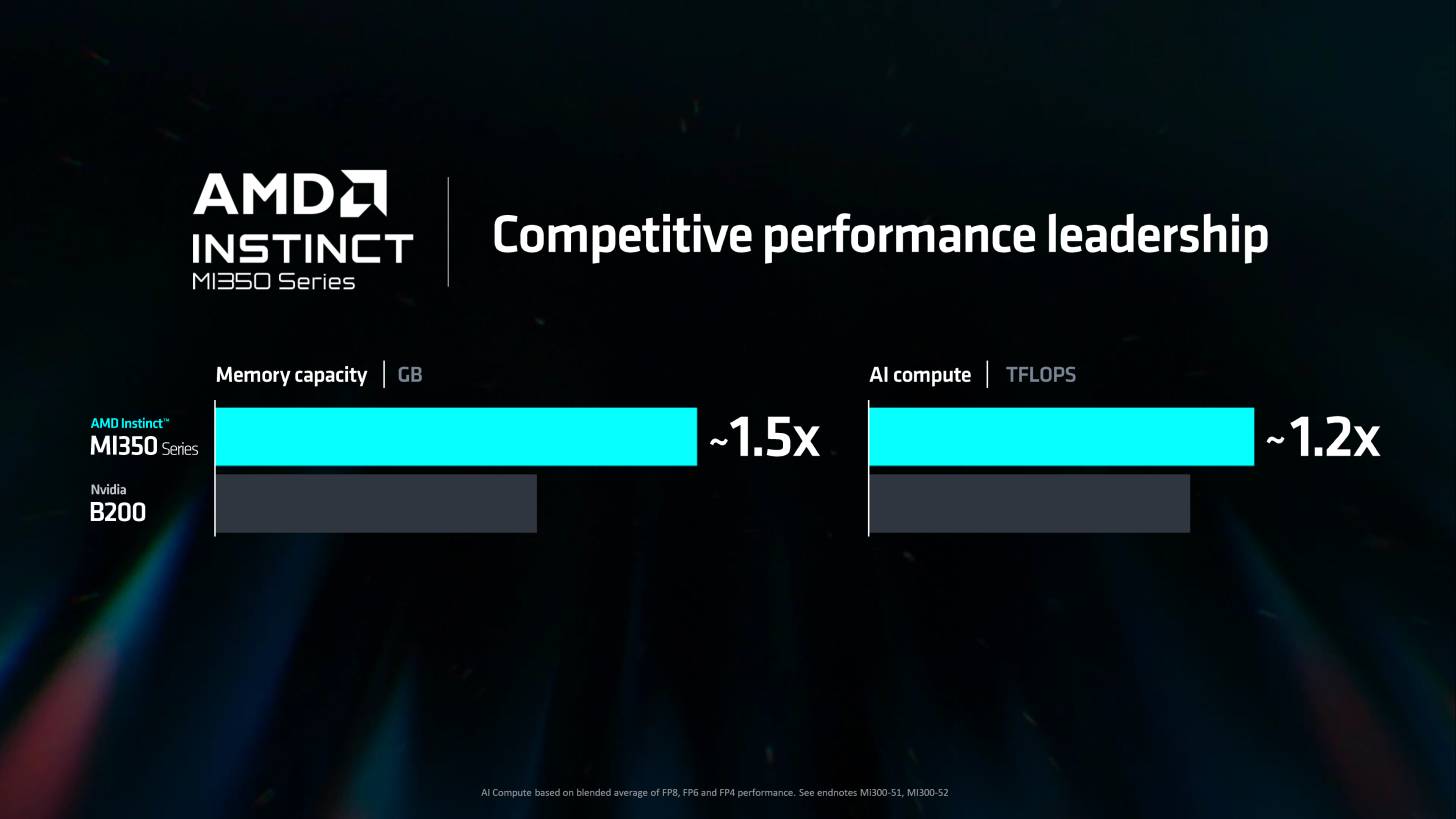
今年リリースが予定されている次期MI325Xは、NVIDIAのHopper H200アクセラレーターを「手際よく」上回ると言われており、今年後半に出荷が予定されているBlackwell B100に対しても、いくつかの点で競争力がある。次世代MI350シリーズは、CDNA 4アーキテクチャを採用し、Blackwell B200に対抗する。
NVIDIAのB200とAMDのMI350シリーズは、いずれも2025年の量産開始を予定しているため、この戦いは接戦となり、興味深いものとなるだろう。
この2つについては、Nvidiaの製品の登場と当社の同世代製品の登場とのギャップを縮めていると考えています。ですから、[MI]325[X]はH200を凌駕し、多くの点で[Nvidiaの次期]B100と競合していると言えるでしょう。そして、明らかにH200より少し遅れて発売されるでしょう。
そして、[MI]350(CDNA 4 GPUアーキテクチャをベースとする)は、[Nvidiaの]B200の予測よりも高いパフォーマンスを発揮する素晴らしいものだと思います。B200は、どのようなボリュームでも2025年の製品だと考えており、[MI]350も同様です。
フォレスト・ノーロッド – AMD幹部 (CRNより)
NVIDIAのGB200 Grace HopperとGrace Blackwellソリューションについて言えば、AMDはCPUとGPUの両アーキテクチャを最適化することは良いことであり、エグザフロップスの壁を初めて突破し、このような高い計算能力を持つ地球上で最も効率的なスーパーコンピュータであるFrontierスーパーコンピュータ向けにEPYC(Trento)とInstinct MI250(GPU)をリリースすることで、この部門ですでにいくつかの下準備ができていることを認めている。

MI300Aシリーズでは、AMDはAPUという形でよりタイトなパッケージを提供しているが、APUの需要が常にあるとは限らない。
AMDはまた、UE(Ultra Ethernet)プラットフォームとUAL(Ultra Accelerator Link)プラットフォームに支えられたオープン・エコシステムについても語っている。
UEプラットフォームは、顧客により多くの選択肢を提供し、デザインチョイスを容易にし、例えばNVIDIAを使用することに伴うプロプライエタリな性質を心配することなく、CPU、GPU、アクセラレータ、その他のIPを使用することを可能にする。

※ 画像をクリックすると別Window・タブで拡大します。
最後に、フォレストはIntelと最近公開されたGaudi 3アクセラレータの価格について、定価は完全に時間の無駄だと反撃している。
AI関連のすべての発表において、IntelはGaudiプラットフォームの競争力を強調しているが、AMDは、IntelのAI製品の10%以上が公表された価格で販売されたとしたら非常に驚きであり、マーケティング上のたわごとのように見えるだろうと述べている。


※ 画像をクリックすると別Window・タブで拡大します。
NVIDIAは依然として圧倒的な市場シェアでリードしているが、AMDとIntelはこの分野に非常に力を入れているようだ。全体として、このインタビューは非常に興味深い内容となっている。
解説:
AMDがInstinctシリーズがNVIDIAにAIアクセラレーターにより注力させていると発言
当のNVIDIAはIntelのOneAPIのほうを意識しているような発言をしていますが、現時点で売れているのはやはりAMDのほうです。
ROCmは2017年に最初のバージョンを公開してから7年経っています。
そこからひたすらCUDAのとの互換性の高いソフトウェアを開発し続けてきたことがここにきて花開いていると思います。
現時点でのROCmを見ていると業界のリーダーシップをとれるかと問われれば答えは微妙ですが、CUDAとの互換性は市場から一定の評価を得られていると思います。
ROCmの独自性(CUDAより優れているところ)は主にMI300シリーズ向けの機能のようですので、RDNA3でしか使ったことのないわたくしにはよくわかりません。
しかし、RDNA3から見たROCmはCUDAの下位互換といったところです。
RDNA4ではぜひともCUDAの機能や性能を超えるレベルまで行ってほしいところではあります。
MI300シリーズはNVIDIAの1/11程売れているので、最適化やノウハウについてひろまっでほしいところです。
あくまでも画像生成AIから見た視点でいうと、今のところ各WebUIはROCmへの最適化はされていません。
そのため、同世代のNVIDIA製品に対してはイーブンの性能を発揮できているとはいいがたいです。
このあたり、ハードウェアとソフトウェア、両方の最適化が進めばある程度同世代のGeforceに対して競争力が出てくるのではないかと思います。
RDNA4世代からFSRもようやくアップスケールにAI機能を使用するようですから、これから本格的にAI/ML機能が取り入れられていくと考えてよいのではないかと思います。
ROCmのほうも6.1.xを公開して以来、次のバージョンの開発が進んでいません。
AMDが最も力を入れていると発言しているだけにこの辺りも気になるところです。
Copyright © 2024 自作ユーザーが解説するゲーミングPCガイド All Rights Reserved.