

AMDの “Strix Point””Ryzen AI 9 365” Zen 5 APUがデビッド・ファン氏によってテストされたと報じられ、IPC、レイテンシ&パフォーマンスの詳細な分析が行われている。
AMD Ryzen AI 9 365 “Strix Point” APUが発売に先駆けて多数のベンチマークでテストされ、Zen 5のIPC、スループット、レイテンシなどが詳細に分析されている。
注 – David Huang氏のブログによると、ここで言及されている数値は、AMD Strix Point APU、主にRyzen AI 9 365のエンジニアリング・サンプルに基づくものであり、最終製品を代表するものではない可能性があるため、割り引いて考えてほしいとのことだ。
また、テストシステムは非公式のシステム・ファームウェア/ソフトウェアを実行していたことも明言している。
※ 画像をクリックすると別Window・タブで拡大します。
手始めにデビッドは、Ryzen AI 9 365 SKUを搭載しているとされる初期のAMD Strix Pointラップトップにアクセスした。
このテスト・プラットフォームでは、32GB容量のLPDDR5x-7500メモリを使用した。
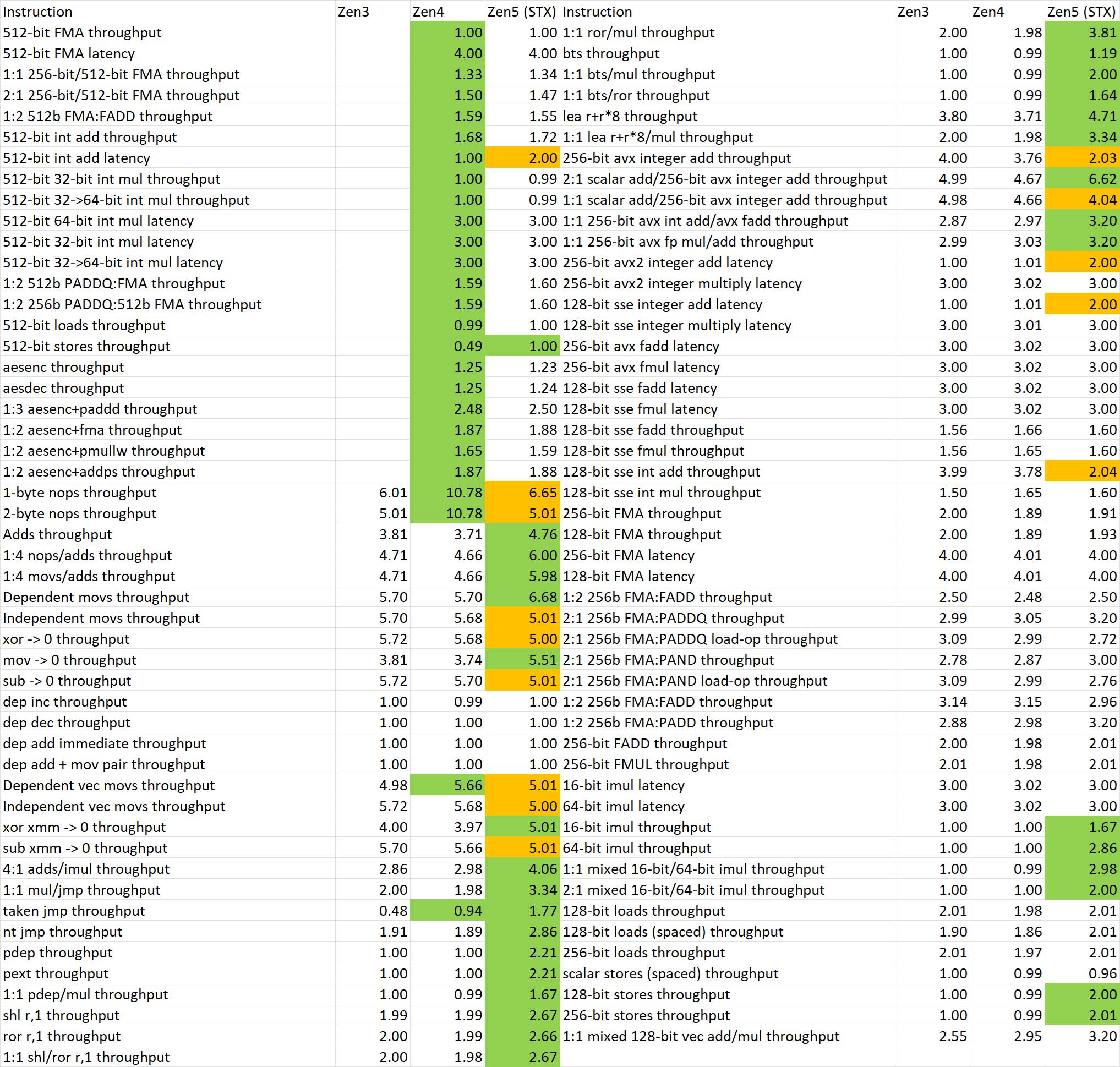
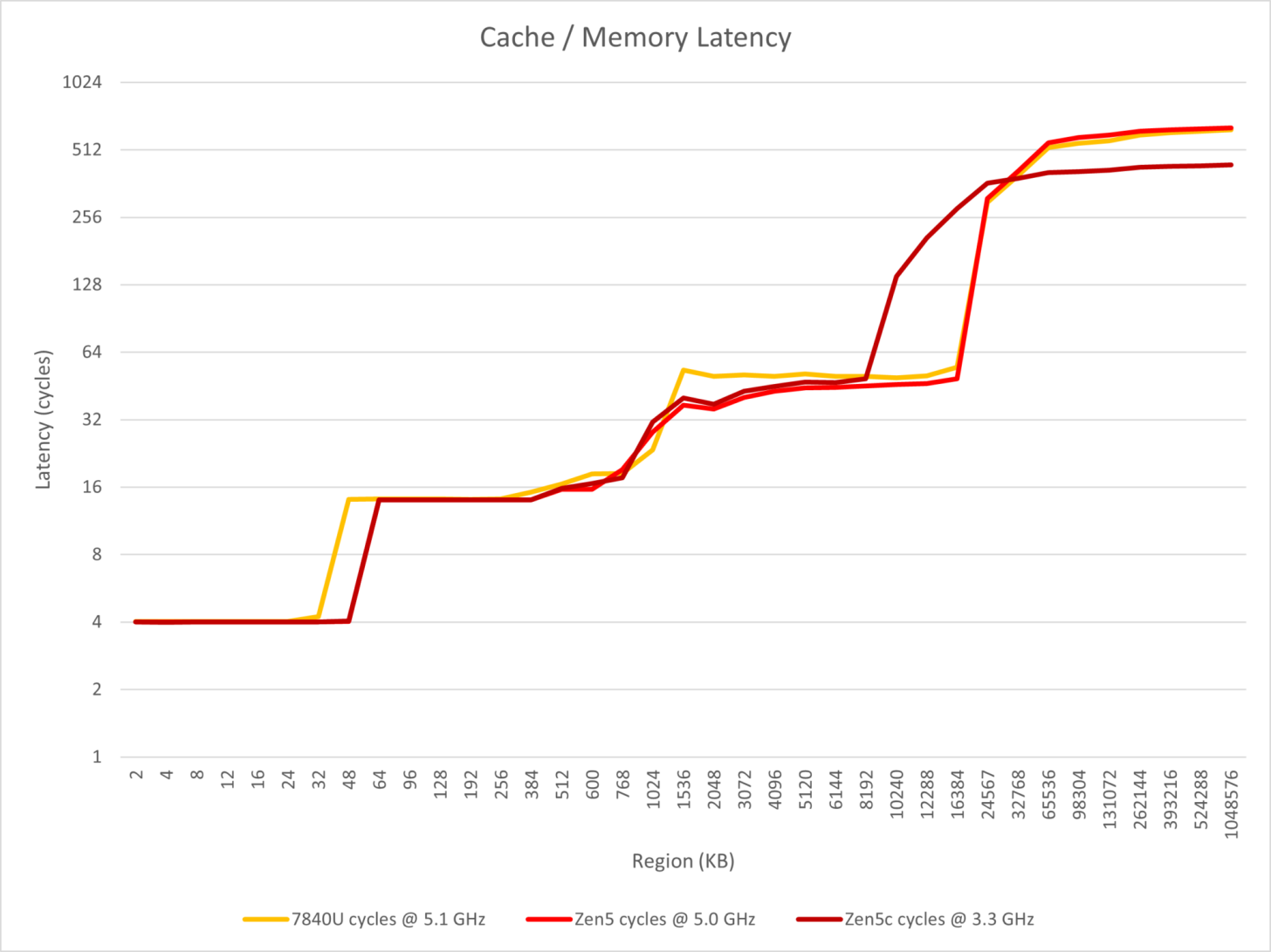
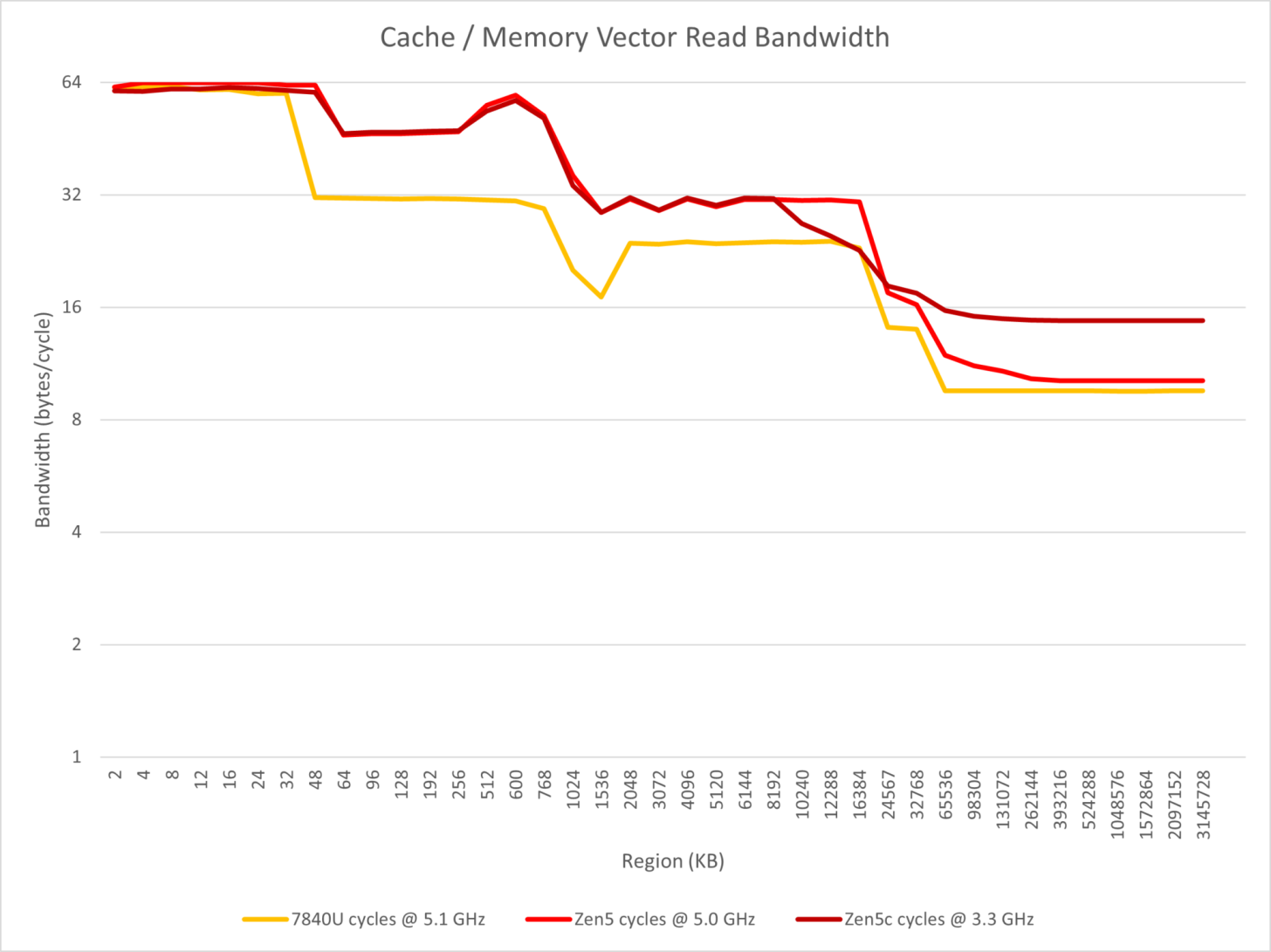
今日のテストの主な焦点はIPCとスループットで、InstructionRateツールでZen 3、Zen 4、Zen 5アーキテクチャを含む3世代のZen CPUの命令スループット/レイテンシを測定することから始まる。
※ 画像をクリックすると別Window・タブで拡大します。
デビッド氏は、Zen 5はグランドアップ設計のおかげで改善されているが、アーキテクチャには以下のような欠点もあると指摘する:
- さまざまなスカラーALU命令のスループットは大幅に向上しているが、モバイルZen 5ではデスクトップやサーバーに比べてベクター・ユニットの数が半減しているため、このテストにおけるSIMDスループットはZen 4と変わらない。ベクター・ユニットが半分になったZen 5コアでも、すべての幅のSIMDストア演算は前世代に比べて2倍になり、SIMDロード・ストアのスループットは1:1に達する;
- 分岐処理能力は大幅に強化され、1サイクルで処理できる非採用分岐は2つから3つに増え、1サイクルで処理できる採 用分岐は2つになった。これは新しいフロントエンド設計と関係があるはずだ;
- 128/256/512ビットのSSE/AVX/AVX512 SIMD整数加算計算のレイテンシがすべて2サイクルに増加した。この変更は、高周波数を維持しやすくするためと思われる。
- 128/256bit SIMD整数加算演算のスループットはZen 4に比べて半減しているが、512bitは変わっていない。この問題はSIMDが半分になったZen 5コアにのみ存在し、ポート割り当てに関係しているのではないかと推測されています;
- Zen 4で導入されたnopフュージョン機能が削除され、nop命令を同じマクロop上の別の命令とマージすることができなくなりました;
- 一部の論理レジスタ操作のスループットを調整し、一部の mov 操作と一部のレジスタ・ゼロ化操作のスループットを 5 に統一。
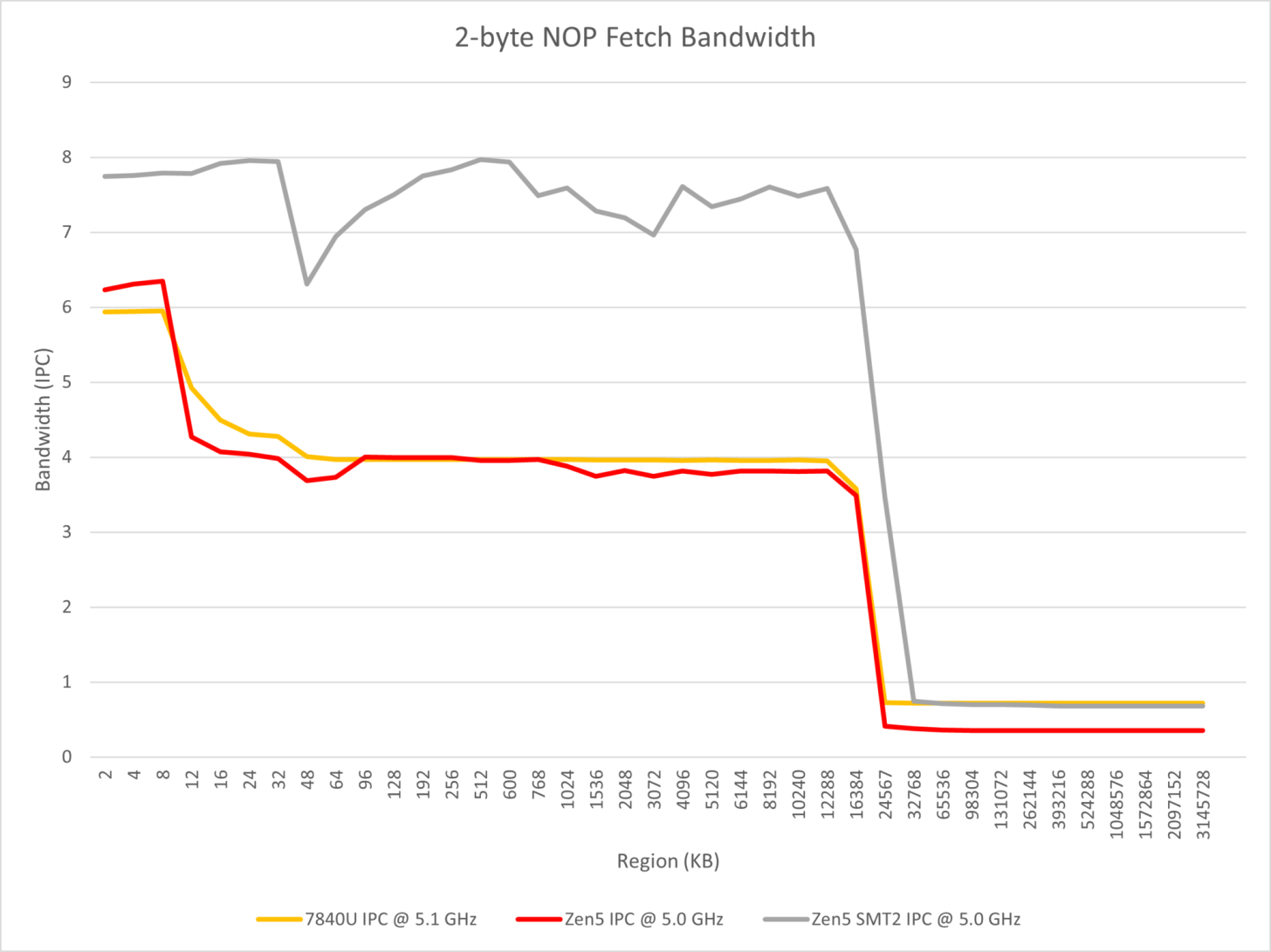
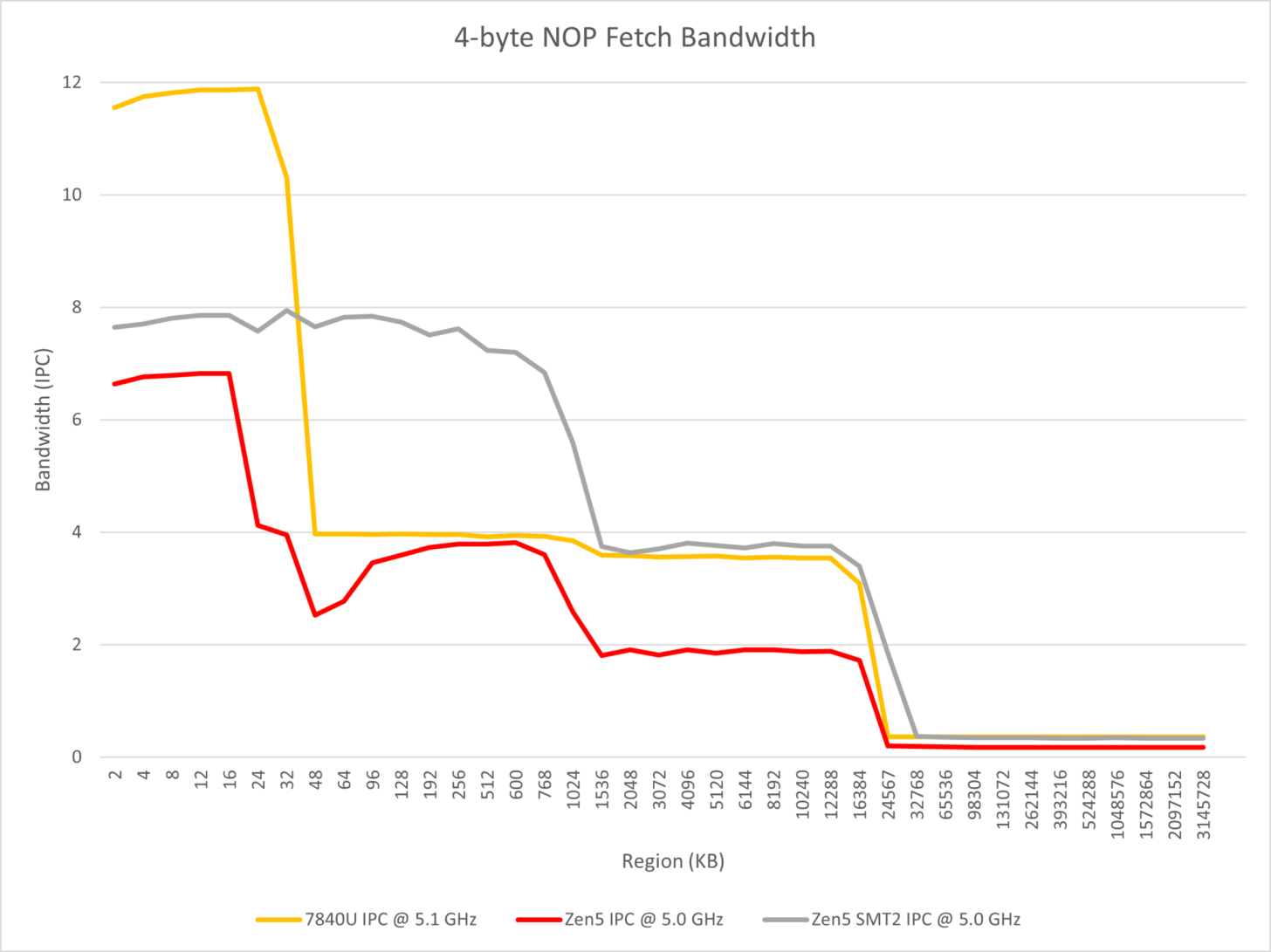
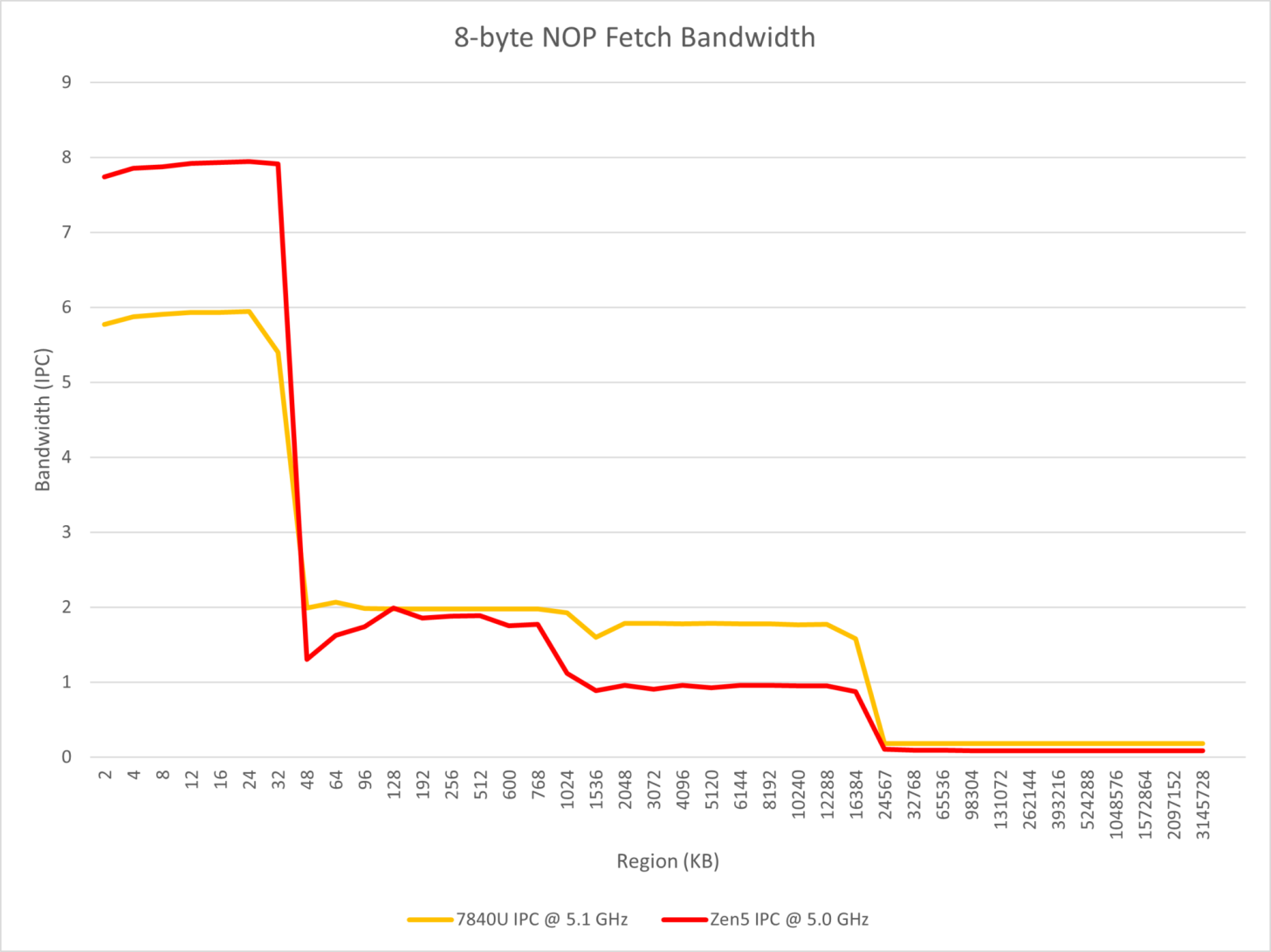
このテストでは、命令フェッチ、デコード、マクロオペキャッシュに影響を与えるパラレルデュアルパイプフロントエンドにも焦点を当てている。
異なる長さと数のNOP命令を実行することで、Zen 4とZen 5の違いを観察できると述べている。観察の結論は以下の通りである:
- Zen 5はTremontに似たマルチフロントエンド・デザインを採用していますが、8ワイドのリネームを実装するために、2つの4ワイドx86デコーダと少なくとも8ワイドのマクロオプ・キャッシュを使用しています;
- 次の現象を考えてみよう。
- Zen 5では、1つのスレッドで連続したNOP命令を実行する場合、x86のデコード帯域幅を4以上にすることはできません;
- 命令スループットのセクションでは、2つの分岐を1サイクルで処理できることがテストされています;
- Zen 5では、GracemontのようなプリデコードILDキャッシュ・ソリューションを使用せず、分岐予測器が分岐を予測した場合に2つのデコーダを同時に動作させる、つまり、一方のデコーダに次の分岐先アドレスから直接デコードを開始させる必要があると推測するのは妥当である。この観点から、AMDはスパース分岐のあるシナリオで高いスループットを達成するために、依然としてマクロオペ・キャッシュに頼る必要がある。
- Zen 5は、同じサイクルで2つのロケーションからのx86命令のデコードをサポートするだけでなく、同じサイクルでマクロオプキャッシュの2つのロケーションからの命令のフェッチもサポートしており、マクロオプキャッシュのカバレッジ内で1サイクルあたり2回の分岐を実現している;
- コアが2つのSMTスレッドを実行する場合、それぞれがデコーダを独占できるため、ほとんどの場合、コア全体のx86デコード・スループット限界は8に達する。
※ 画像をクリックすると別Window・タブで拡大します。
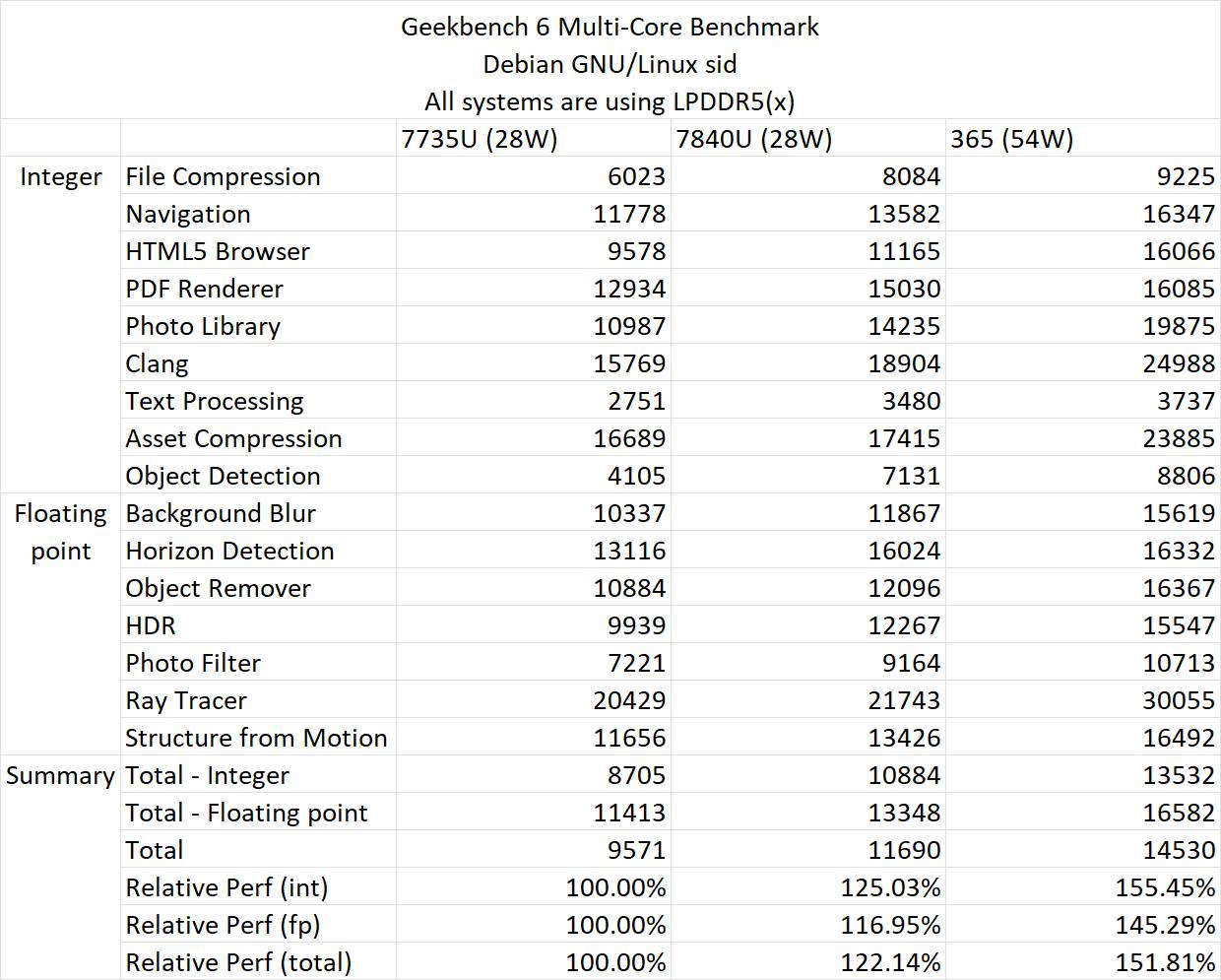
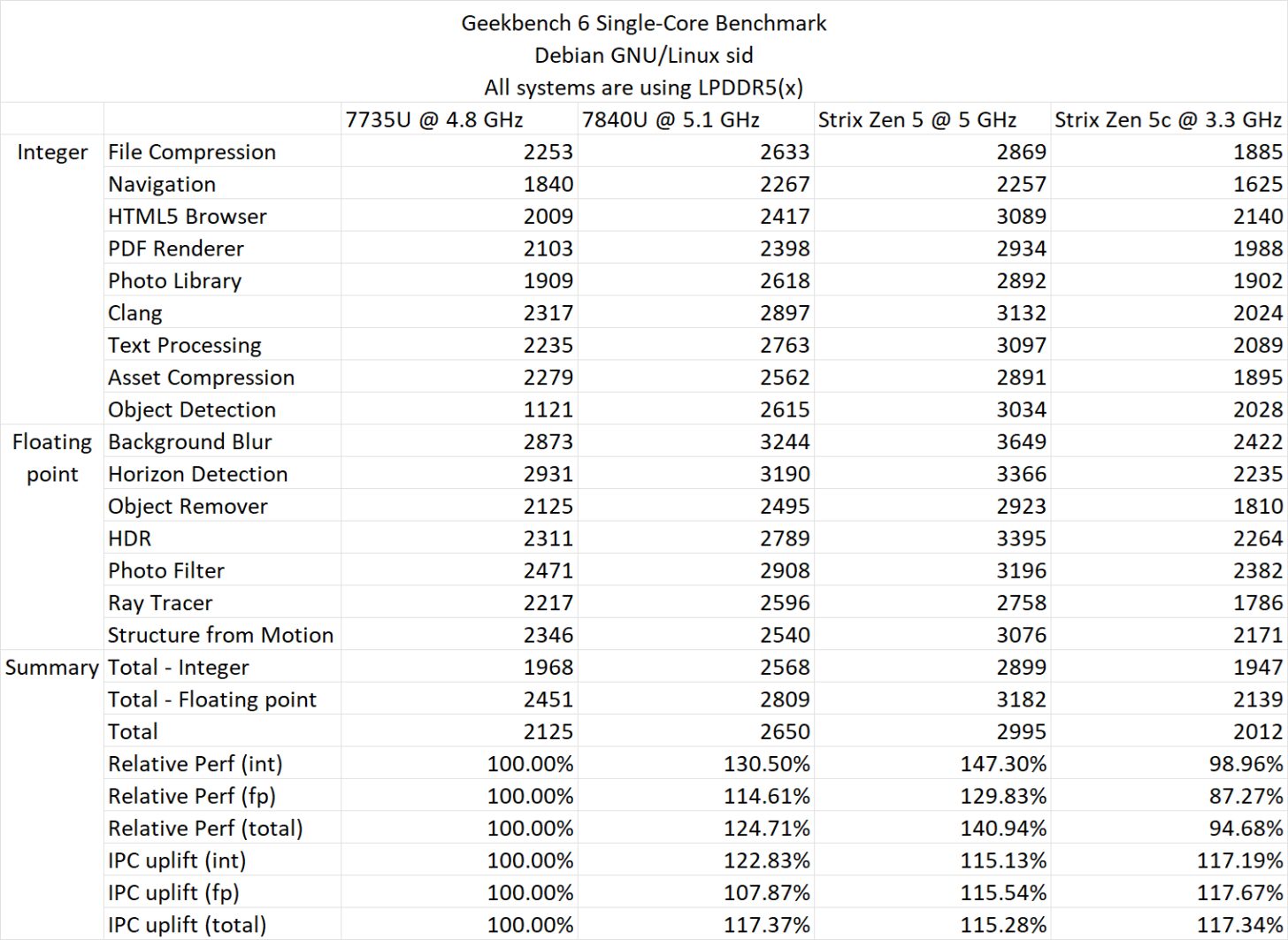
テストは次に、AMD Strix Point APUのよりパフォーマンス面へと進む。今回もRyzen AI 9 365チップが使用されているが、今回はRyzen 7 7735U(Zen 3)、Ryzen 7 7840U(Zen 4)、そして前述のRyzen AI 9 365(Zen 5)と対戦している。
Zen 5Cコアはわずか3.30GHzとかなり低いクロックで動作し、Zen 5コアと他の2チップは4.8GHzの固定クロックに設定されている。
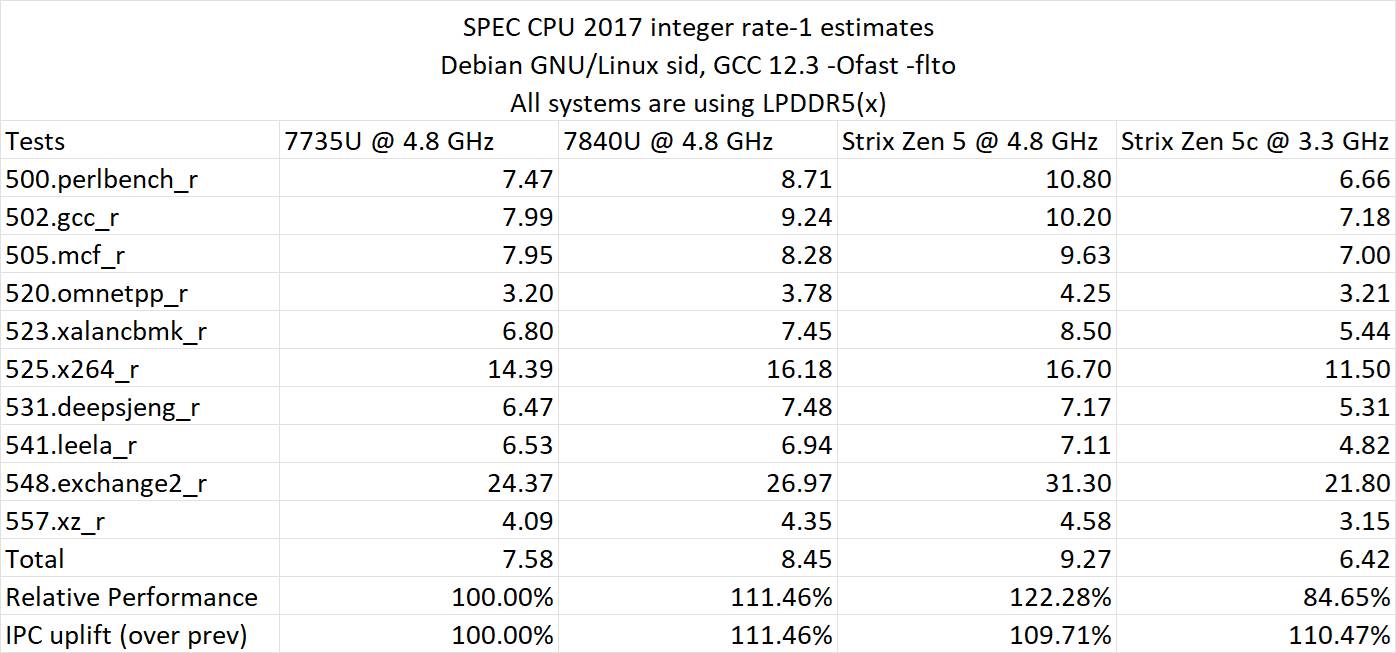
性能はSPEC CPU 2017とGeekbench 6(シングルコアとマルチコア)で評価された。SPEC CPU 2017では、AMD Zen 5チップはZen 4に比べて+9.71%、Zen 3に比べて22.28%向上している。
Zen 5Cコアは、低クロックでZen 4のIPCにほぼ匹敵する。
※ 画像をクリックすると別Window・タブで拡大します。
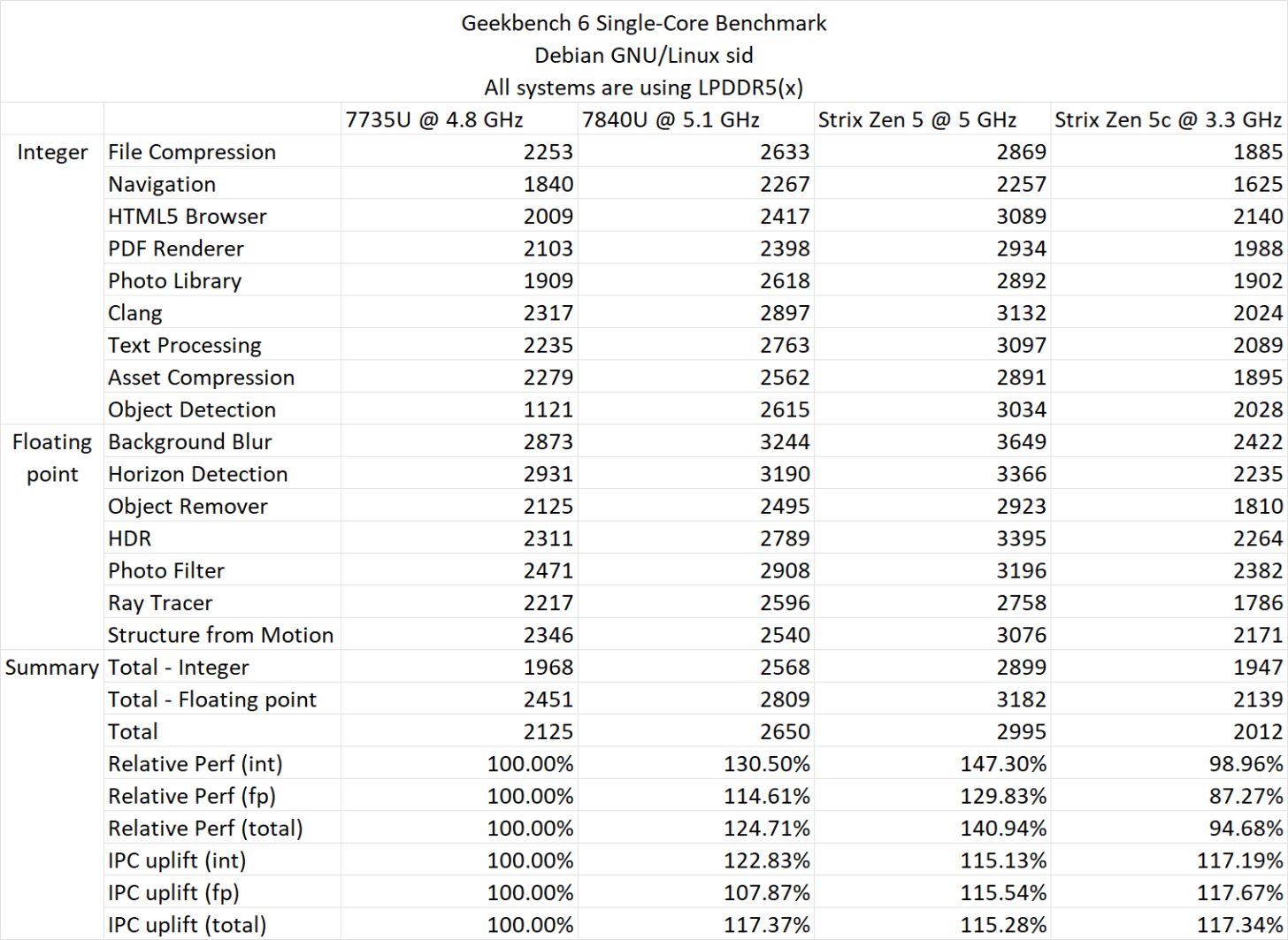
Geekbench 6では、Zen 3に対する相対的な性能向上は最大40.94%で、Zen 3とZen 4では約13.1%となっている。
これらの数値はシングルコアのみでの数値である。
マルチコアテストでは、Zen 5 “Strix Point” APUはZen 3に対して55.45%、Zen 4に対して24.3%向上しているが、Ryzen AI 9 365 APUの54Wに対して、Zen 3とZen 4チップは28WのTDPで動作していたことに注意する必要がある。
SPEC CPU 2017 IPC (世代間)
- Zen 3 – 100.00
- Zen 4 – 111.46
- Zen 5 – 109.71
SPEC CPU 2017 Perf(相対値)
- Zen 3 – 100.00
- Zen 4 – 111.46
- Zen 5 – 122.28
Geekbench 6 ST IPC (世代間)
- Zen 3 – 100.00
- Zen 4 – 117.37
- Zen 5 – 115.28
Geekbench 6 STパフォーマンス(相対値)
- Zen 3 – 100.00
- Zen 4 – 124.71
- Zen 5 – 140.94
デイビッドのブログ記事では、Ryzen AI 300「Strix Point」APUだけでなく、Ryzen 9000「Granite Ridge」デスクトップ・ファミリー、第5世代EPYC「Turin」サーバー・ファミリー、デスクトップおよびラップトップ・プラットフォーム向けの各種APUなど、さまざまなCPUに搭載されるZen 5アーキテクチャのさまざまな側面について、幅広く言及している。
公式に分かっているのは、Zen 5コアの平均IPCは16%向上し、ワークロードによって幅があるということだ。
Zen 5の最初のローンチは7月中旬のStrix APU、そして7月下旬のRyzen 9000高性能デスクトップ・チップとなる見込みである。
解説:
Zen5APUのパフォーマンスリーク、概ね良好だが・・・
Zen5「Ryzen AI 9 365」の性能がリークしました。
性能は順当に進化しており、問題のないレベルだと思います。
Zen5世代の最大の問題点。
Zen5の性能については上の記事に詳しいですからそちらを読んでいただくとして、解説ではZen5世代の現在わかっている性能以外の問題点指摘していこうかと思います。
問題点1 Copilot+への対応
こちらはすべてのデスクトップCPUにいえることですが、デスクトップのCPUはCopilot+に対応しているのかどうかというところです。
Copilot+に対応しているかどうかはマイクロソフトがSoCを認定するかどうかにかかっています。
条件をクリアしていたら大丈夫なのだと思いますが、マイクロソフトが認めなければCopilot+は名乗れません。
※ Ryzen AIは対応しています。
Ryzen9000シリーズのデスクトップ版はNPUが内臓されているとは明言されておらず、おそらくNPUの内臓はされていないのでしょう。
だとするとせっかく新しいCPUを買ってもCopilot+は名乗れないということになります。
問題点2 RadeonがGPGPUに対応していない(ROCmに対応していない)
当サイトの読者さんならわかっていると思いますが、RadeonはWindowsでROCmに対応していません。
NVIDIAは独自のAI PCの規格としてRTX AI PCというものを打ち出していますが、AMDは今のところそうしたことはできないということになります。
つまり、Copilot+を中心にしたAI PCという流れにデスクトップ版のRyzen9000シリーズは乗れないということになります。
※ Ryzen AIは対応しています。
IntelのArrowLakeにNPUが内臓されているのかどうかはわかりませんが、仮に内臓されていた場合、同世代の製品でAMDだけCopilot+に対応できないということになります。
わたくしは以前からこの疑問点を指摘してきましたが、Copilot+対応SoC発売前夜になってもいまだに何の音沙汰もないのは気になるところです。
2024年からはAI PCというのが一つの大きな焦点になっているだけに、デスクトップ版RyzenもRadeonもそこから締め出されている状態なのはセールスに大きな影響を与えるのではないでしょうか。
今年後半から新製品が発売されますが、ぜひとも単体GPUであるRadeonを使えばAMD製品で固めてもAI PCを名乗れるようになってほしいところです。
鍵を握っているのはWindows版のROCmでしょう。
当サイトでも「前夜祭」としてZLUDAを使ったStable Diffusion WebUIセットアップスクリプトを配布していますが、早いところ公式でもアナウンスを期待したいところです。
最悪、AI PCを使いたい人はRyzen9000デスクトップ版ではなく、Strix Pointのデスクトップ版を待ったほうが良いという可能性もあります。
この辺りはAMDのソフトウェアサポートの弱さがモロに出てしまっています。
AMDのGPU Radeonシリーズ
Radeon 7000シリーズ





Radeon RX 6000シリーズ



※ SAPPHIREはAMD Radeon専業のメーカーであり、Radeonのリファレンス的なメーカーです。
Copyright © 2024 自作ユーザーが解説するゲーミングPCガイド All Rights Reserved.