

AMDの特許出願により、同社が「マルチチップレット」GPU設計オプションを模索していることが明らかになり、次世代RDNAアーキテクチャが大規模な変更を特徴とするかもしれないことが示唆された。
AMDは次世代RDNA GPUにマルチチップレット・アプローチを採用することで、モノリシック設計からの脱却を目指すようだ。
MCM(マルチ・チップレット・モジュール)のコンセプトは、グラフィックス・セグメントにとってまったく新しいものではないが、モノリシック設計の限界により、業界におけるMCMへの傾斜は確実に高まっている。
AMDは、マルチチップレット設計の経験が豊富な企業の1つであるようだ。同社のAIアクセラレーター「Instinct MI200」のラインナップは、GPC(グラフィックス・プロセッシング・コア)、HBMスタック、I/Oダイなど、複数のチップレットを1つのパッケージに積み重ねたMCM設計を初めて採用した。
同社はまた、Navi 31などの最新のRDNA 3アーキテクチャにMCMソリューションを搭載した最初の企業でもある。
しかし、新しい特許により、チームレッドはこの思想をメインストリームの「RDNA」アーキテクチャに反映させようとしている。
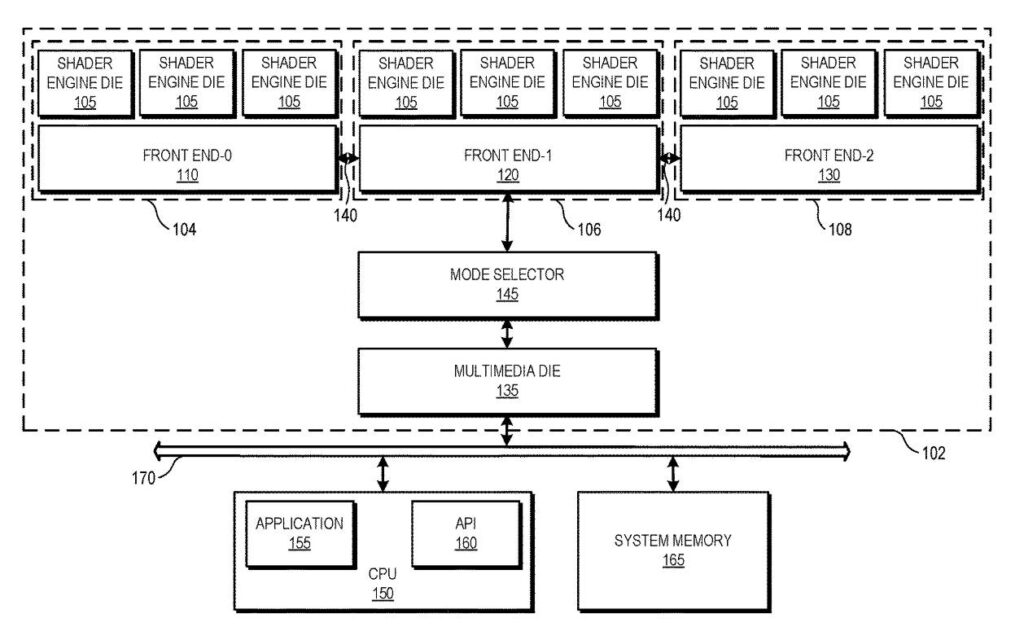
この特許では、3つの異なるチップレット利用「モード」の使用について説明されており、その違いはリソースの割り当て方法と先の管理方法にある。
特許は3つの異なるモデルを明らかにしており、最初のものは「シングルGPU」モードで、現代のGPUが機能する方法とよく似ている。
オンボードのすべてのチップレットが単一の統合処理ユニットとして機能し、リソースは協調環境で共有される。
第2のモードは「独立モード」と呼ばれ、個々のチップレットが独立して動作し、関連するシェーダーエンジン・ダイのタスクスケジューリングを担当する専用のフロントエンド・ダイを通じて、それぞれの機能を担当する。3つ目のモードは最も楽観的で、「ハイブリッド・モード」と呼ばれ、チップレットが独立して動作し、かつ共存することができます。
統合処理と独立処理の両方の利点を活用し、スケーラビリティと効率的なリソース利用を実現します。

この特許では、AMDのMCM設計のアプローチに関する詳細は明らかにされていないため、チーム・レッドが特許に記載されているアイデアを採用するかどうかについてはコメントできない。
しかし、一般的にマルチ・チップレット構成について話すと、マルチ・チップレット構成は性能のレバレッジとスケーラビリティを提供する一方で、その製造はより複雑なタスクであり、ハイエンドの設備とプロセスを必要とするため、最終的にはコストも増加する。
特許では、マルチ・チップレット・アプローチを次のように説明している:
GPUを複数のGPUチップレットに分割することにより、処理システムは、動作モードに基づいてアクティブなGPU物理リソースの量を柔軟かつコスト効率よく構成します。
さらに、構成可能な数のGPUチップレットが単一のGPUに組み立てられるため、少数のテープアウトを使用して、異なる数のGPUチップレットを有する複数の異なるGPUを組み立てることができ、さまざまな世代の技術を実装するGPUチップレットからマルチダイGPUを構築することができます。
現在、AMDはコンシューマー・セグメント向けの適切なマルチGPUダイ・ソリューションを持っていない。Navi 31 GPUはまだシングルGCDのモノリシック設計ですが、インフィニティ・キャッシュとメモリ・コントローラを搭載するMCDはチップレット・パッケージに移されています。
次世代RDNAアーキテクチャでは、AMDは複数のGCDがそれぞれ専用のシェーダーエンジンブロックを持つマルチチップレットパッケージをさらに強化すると予想される。
AMDはこのようなGPUをRDNA 4のラインアップに「Navi 4X/Navi 4C」というコードネームで計画していたが、よりメインストリーム向けのモノリシック・パッケージを採用するために中止したと伝えられている。

また、チーム・レッドがすでにマルチチップの実験を行っていることを考えると、将来のRDNAアーキテクチャがモノリシック設計から脱却するというなら、MCM設計の採用も増加する可能性がある。
解説:
AMDが将来的にMCMを採用?
いや、InstinctでMCMは採用しているので正確な表現ではないと思います。
ゲーム向けのGPUってことなんですかね。
知っての通り、GB202でMCMを採用するといわれていたGeforceはモノリシックに変更になりました。
やはりGCDとMCDのようにバス幅を制限しない限りチップレット間通信の帯域幅やレイテンシが問題になるということですね。
バス幅をHPCのクラスタようにそれほどレイテンシが問題にならない用途ならばMCMでもよいのかもしれませんが、最近のモニターのように240Hzや360Hzといったほぼ上限のない世界になり、フレーム生成のような技術が出てきて、1フレームの表示の前にいくつもの処理が入るようになるとわずかの遅延でも致命的になります。
某格闘ゲーマーの漫画ではありませんが、「俺たちにとっては光の速さですら遅すぎる」という奴です。
これは光回線で繋いでも距離が離れると遅延が問題になり、処理に影響が出てくることを指摘したセリフですが、60FPSを表示するということは1/60で全ての処理を終わらせなくてはならないということであり、それはすなわち0.0167秒=16.667ミリ秒ということです。
1フレームの処理にこだわる人たちは人間もコンピューターもこの違いが分かる人ということになります。
現代のゲームでは莫大な数の3D処理を行っており、年々進化するコンピューターですらも容易ではない処理速度ということになります。
一例を挙げるとAMDのRadeon Anti-LAGは入力を処理するタイミングをぎりぎりまで遅らせているといわれています。
このように涙ぐましい努力をして、レイテンシを削っているということです。
コストを厭わなければ帯域幅は広げればよいですが、レイテンシはある意味どうしようもないところがあります。
ちなみにDLSS3にも若干の遅延が発生するといわれていますが、ゲームのプレイに影響は出ないとされています。
GCDを分割するにはやはりこのレイテンシや帯域幅の問題を解決しなければならないでしょう。
GB202がモノリシックになったのはこの問題を解決するのが難しかったのでしょう。
※ 不可能ではなかったと思いますが、当初はMCMのうわさが出ていたことを考えるとモノリシックにする以上のコストがかかったのではないかと思います。(CoWoSの容量が問題になっている可能性もありますね。)
CPUの場合、Zen2で初めてMCMになり、チップレット間の通信が発生するといまいち性能が出なくなる問題が出ていました。
これらの問題がさらに致命的になるGPUで同じような癖が出ると、動作に引っ掛かりが起きたり、特定の状況下でFPSが落ちたりすることになると予想できますが、さて、AMDはこの問題をどのように解決するのでしょうか。
NVIDIAはもともとMCMと言われていたものをモノリシックにするという力業で何とかしようとしていますが、おそらくははRDNA5の上位SKUで採用されると思われるMCMで詳細がわかるのではないかと思います。
まあ、2026年の話ですから今から語っても仕方ないかなとは思いますが・・・・。
AMDのGPU Radeonシリーズ
Radeon 7000シリーズ





Radeon RX 6000シリーズ



※ SAPPHIREはAMD Radeon専業のメーカーであり、Radeonのリファレンス的なメーカーです。
Copyright © 2024 自作ユーザーが解説するゲーミングPCガイド All Rights Reserved.