

AMDは、RDNA 3 GPUおよびXDNA NPUハードウェアのコンシューマー中心のAIワークロードにおける能力に関する興味深いデータを発表した。
AMDのRDNA 3 GPUとXDNA NPUは、PCプラットフォーム上で消費者中心のAI機能の堅牢なスイートを提供する
AMDがRyzen APUにXDNA NPUを実装することで、より多くのPCユーザーにAI機能を提供する上で先鞭をつけたことは間違いない。
最初のNPUは2023年にPhoenix「Ryzen 7040」APUで発表され、最近ではHawk Point「Ryzen 8040」シリーズでアップデートされた。
NPUのほかにも、AMDのRDNA 3 GPUアーキテクチャには、これらのワークロードを処理できる専用のAIコアが大量に組み込まれており、同社はROCmソフトウェア・スイートでその勢いを確固たるものにしようとしている。


最新の「Meet The Experts」ウェビナーで、AMDは、RDNA 3シリーズなどのRadeonグラフィックス・スイートが、ゲーマー、クリエーター、開発者に、以下を含むさまざまな最適化されたワークロードを提供する方法について説明しました:
- ビデオ画質の向上
- 背景ノイズ除去
- テキスト-トゥ-イメージ(GenAI)
- 大規模言語モデル(GenAI)
- 写真編集
- ビデオ編集
- アップスケーリング
- テキストから画像へ
- モデルトレーニング(Linux)
- ROCmプラットフォーム(Linux)

AMD RDNA 3グラフィックス・アーキテクチャを始め、Radeon RX 7000 GPUとRyzen 7000/8000 CPUに搭載された最新のGPUは、2倍以上の世代間AI性能の向上を実現します。

これらのGPU製品は、FP16ワークロードに最適化された最大192個のAIアクセラレータを提供し、Microsoft DirectML、Nod.AI Shark、ROCmなどの複数のMLフレームワークで最適化されており、大容量データセットの処理に不可欠な専用VRAMの大容量プール(最大48GB)を備え、Infinity Cacheテクノロジーによって高速な帯域幅も実現している。

AMDによると、PCプラットフォームにおけるAIのユースケースの大半はLLMとDiffusionモデルであり、これらは主にFP16コンピュートと実行するハードウェアのメモリ性能に依存している。
SDXL(Diffusion)のような特定のモデルは、演算性能によって制限され、約4~16GBのメモリを必要とする一方、Llama2-13BとMistral-8x 7Bはメモリによって制限され、最大23GBのメモリを使用することができる。

前述の通り、AMDはAIアクセラレーション専用のハードウェアを幅広く用意している。同社のRadeon RX 7600 XT(米329ドルのグラフィックカード)でさえ、16GBのVRAMを搭載しており、性能面ではLM StudioでRyzen 7 8700Gの3.6倍、RX 7900 XTは8700Gの最大8倍の高速化を実現している。
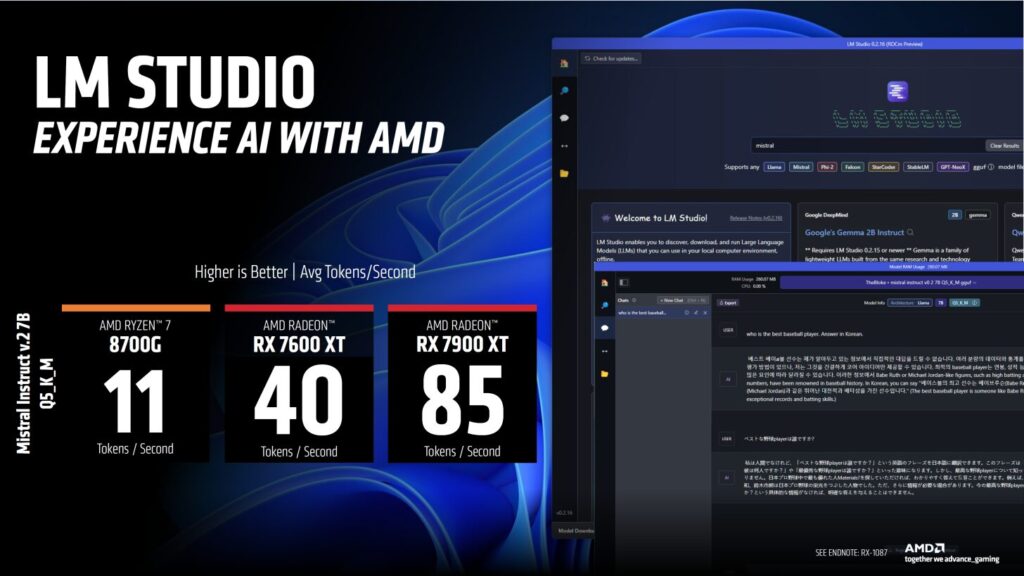
LM Studio のパフォーマンス(高ければ高いほど良い):
- Ryzen 7 8700G NPU:11トークン/秒
- RX 7600 XT 16GB:40トークン/秒
- RX 7900 XT 20GB:85トークン/秒
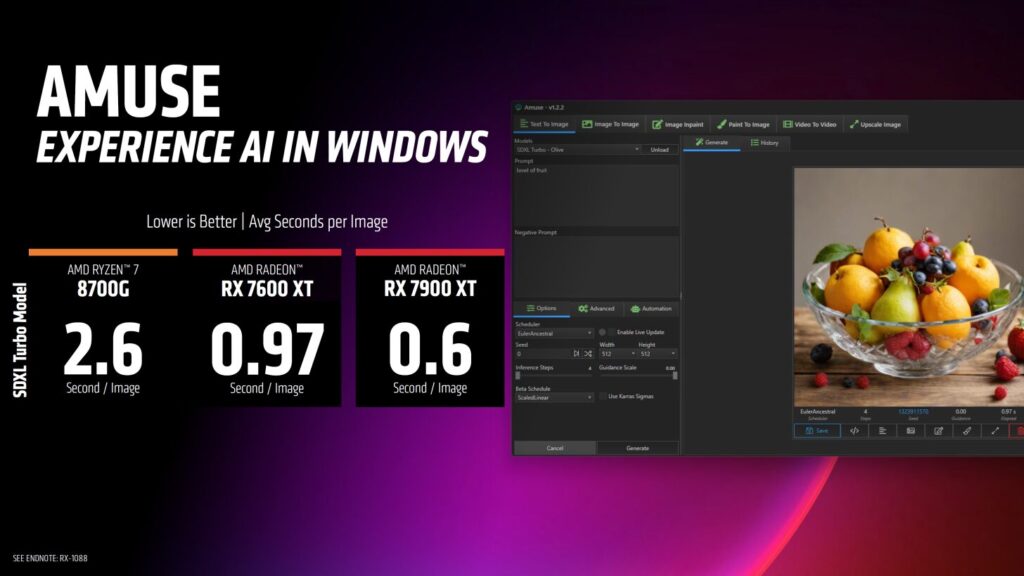
AMUSE Diffusion(低いほど良い):
- Ryzen 7 8700G NPU:2.6秒/イメージ
- RX 7600 XT 16 GB:0.97秒/イメージ
- RX 7900 XT 20GB:0.6秒/イメージ

AMDはまた、グリーンチームが「Premium AI PC」プラットフォームと呼ぶ、NVIDIAのGeForce RTXとの小さな比較も行っている。
どちらのラインナップも同様のサポートを提供しているが、AMDは、NVIDIAの最もエントリーレベルの16GB GPUが約500ドル(4060 TI 16GB)からであるのに対し、同社の16GB GPUが329ドル(7600 XT)という低価格で提供されていることを紹介している。
同社はまた、最大48GBのメモリまで拡張可能なハイエンド・スタックも用意している。
AMDは以前にも、AIでインテルのCore Ultraに対して、より優れた価格で強力なパフォーマンスを示したことがある。



今後、AMDはROCm 6.0がどのように進歩し、オープンソーススタックがRadeon RX 7900 XTX、7900 XT、7900 GRE、PRO W7900、PRO W7800などのコンシューマー向けハードウェアのサポートを受けているかについて語る。
ROCm 6.0は、Ubuntu 22.03.3(Linux)OS上で、PyTorchとONNX Runtime MLモデルとアルゴリズムの両方をサポートし、より複雑なモデル用にINT8を追加することで相互運用性を向上させている。
同社はまた、開発者にさまざまなソフトウェア・スタックとハードウェア・ドキュメントを提供することで、ROCmをさらにオープンソースにしようとしている。








AMDとそのROCmスイートは、支配的なNVIDIA CUDA & TensorRTスタックと競合しており、インテルも独自のOneAPI AIスタックで地歩を固めている。
これらは、PCプラットフォーム上のAIワークロードに関して注目すべき3つの勢力であるため、今後、既存および次世代ハードウェア向けに多くのイノベーションと最適化が行われることが期待される。
解説:
NPUとGPUでどのくらいの性能差があるのかというのをAMDが公式に発表したようですね。
RX7900XTとRyzen 7 8700Gで最大8:1くらいの性能差になるようです。
当然というか予想できた結果ですが、かなり性能差が大きいかなあと思います。
比較に使われているソフトを見ると、LM StudioやAMUSE DIffusionがあります。
LM Studioは現在でもAMD対応のベータ版が手に入りますが、AMUSE DIffusionについてはリポジトリが閉鎖されており、手に入りません。
NVIDIA、Intel、AMDの中でAMDだけがWindowsでStable Duffusionが・・・というよりはpytorchがネイティブに使えません。
最後発のIntelにすら負けているのはいかがなものかと思いますのでぜひとも早くWindows版ROCmをリリースしていただきたいところです。
当サイトでもZLUDAのセットアップスクリプトを配布しておりますが、ROCmさえ出てくれれば、あとは普通にインストールできますので、あんなに苦労することはありません。
本当に「普通に」使えるようになります。
というより、使えるのが当たり前になります。
ZLUDAはHIPを呼び出す互換レイヤーのようになってしまっているので、似たようなことをしているROCmもそんなに苦労せずにリリースできるのではないかと思ってしまいます。
この記事を書いている時点ではROCm6.1のWindows版はまだリリースされていません。
Linux版のセットアップスクリプトは出していますが、やはりWindowsとは反応が違います。
ぜひとも1日も早く、NVIDIA、Intelと同様の環境を提供していただきたいところです。
AMDのGPU Radeonシリーズ
Radeon 7000シリーズ





Radeon RX 6000シリーズ



※ SAPPHIREはAMD Radeon専業のメーカーであり、Radeonのリファレンス的なメーカーです。
Copyright © 2024 自作ユーザーが解説するゲーミングPCガイド All Rights Reserved.